

As an SEO enthusiast, you’ve likely encountered your fair share of robots.txt files. But with the ever-evolving search engine landscape, it’s important to stay up-to-date on best practices. This guide dives deep into robots.txt, exploring its purpose, functionalities, and how to leverage it for optimal SEO.
What is robots.txt?
A robots.txt file is a text file placed on the root directory of your website. It acts as a set of instructions for web robots, primarily search engine crawlers, indicating which pages or directories they can access and crawl for indexing. Think of it as a “crawlers-only” section of your website, this will guide search engines on how to efficiently navigate your content.
What robots.txt can do?
Control Crawling
You can instruct crawlers to disallow access to specific pages, directories, or file types (like images or PDFs). This can be useful to prevent crawling of thin content, duplicate pages, or areas under development.
Improve Efficiency
By strategically blocking unnecessary crawling, you can reduce server load and ensure crawlers prioritize important content.
Hide Content (Not Really)
While you can block crawling, robots.txt doesn’t guarantee a page won’t be indexed. If the page is linked to elsewhere on the web, search engines might still discover and index it, but without the content itself.
What robots.txt cannot do?
Block Indexing
Robots.txt doesn’t prevent pages from appearing in search results. To exclude a page from indexing use the noindex directive in the meta robots tag or password-protect the page.
Enforce Rules
Robots.txt relies on voluntary compliance. Malicious crawlers might disregard your instructions.
How To Create an Effective robots.txt?
Start Simple
If you’re new to robots.txt, begin with a basic structure allowing all crawling. You can refine it later. Here’s a basic template.

This allows all user-agents (search engine crawlers) to crawl all directories.
Block Unnecessary Directories
Disallow crawling of admin directories, login pages, or folders containing temporary files. Here’s a example
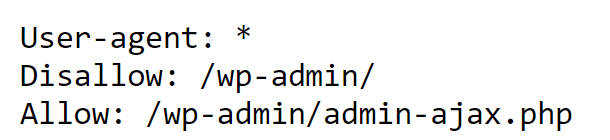
Target Specific User-agents
Use separate directives for different crawlers.
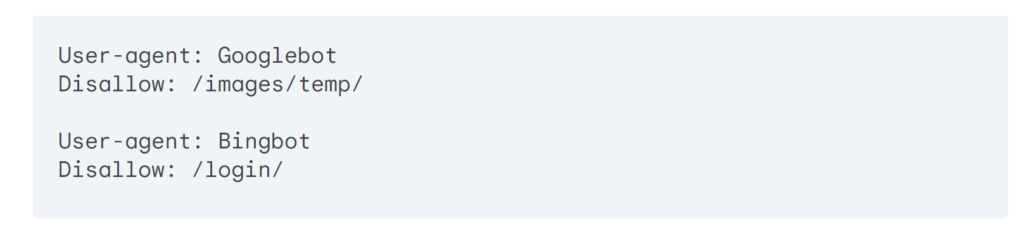
Crawl Budget Optimization
If you have a large website consider strategically blocking low-value content to optimize crawl budget for important pages.
Advanced Uses Of Robots.txt
Allow Crawling with Delays
For pages that might overload your server, use the Crawl-delay directive to slow down crawling.
Sitemap Integration
Include the location of your sitemap at the end of your robots.txt file to help crawlers discover your content efficiently.
Conclusion
By understanding the nuances of robots.txt and implementing it strategically, you can enhance your SEO efforts. Remember, robots.txt works best when used in conjunction with other SEO best practices like high-quality content and a strong backlink profile.
Might Be Useful